
Hey de nuevo por aca en mi libro de Posts tratando de compartir conocimientos con el mundo.
Sigo con el rollo del JavaScript y #NodeJS y hoy traigo algo que hace unos anos era mi rutina y necesidad ya que 10 años atrás no tenía internet en mi hogar. Las conexiones estándar eran Dial Up y la banda ancha era lujo. Por ello me convertí en esa época en un judío errante que buscaba lugares factibles donde posarse y recibir el menor daño posible de la Web y sus entrañas.
No olviden que soy aspirante a desarrollador (nunca es tarde) asi que no juzguen.
No olviden que soy aspirante a desarrollador (nunca es tarde) asi que no juzguen.
Recuerdo ubicar diferentes Cyber Cafes dónde poder con la mayor tranquilidad investigar mis intereses. Tambien instalaba aquel software (siempre en Windows para esos lugares HTTrack) donde podia descargar los sitios "completos" así como sus contenidos y consumirlos en casa. Lo admito en esa epoca sufria del trastorno de acumulacion compulsiva y recababa hasta lo que no era mío en esa maquina que me hospedaba por tantas horas que la alquilaba.
Recuerdo como tenía "asignada" aquella Pc número 11 en la que emulaba mi vertiginoso Turbo Pascal para hacer las prácticas de la universidad. Luego vino Visual Basic, las VBA con Excel, etc.
Recuerdo como tenía "asignada" aquella Pc número 11 en la que emulaba mi vertiginoso Turbo Pascal para hacer las prácticas de la universidad. Luego vino Visual Basic, las VBA con Excel, etc.
Luego adentrándome en la programación un poco más recuerdo a PHP como protagonista de mis primeros intentos del scrapping.
Hoy han pasado 10 años de aquellos vericuetos y me encuentro más maduro, más claro con el conocimiento, pero también más preocupado por lo que no se y por lo que creo saber.
NodeJS es un framework maravilloso y que poco a poco viene ganando mas y mas terreno por su facilidad y por su adaptabilidad a las competencias necesarias actuales.
Veamos apenas un poco de su magia. Vamos a atravesar el DOM para sacar algunos datos de la página cargada. Solo voy a mostrar lo sencillo que hice. Queda de tu parte extraer mayor data y experimentar a ver que tanto se puede hacer.
Lo primero es tener todo el entorno listo para desarrollar.
Voy a mostrar todo el trabajo corriendo en mi Dell Inspiron 5720 con Ubuntu 16.10 como OS matriz. Tengo instalado NODEJS y mis dependencias básicas son CHEERIO.JS y REQUEST.JS.
Vamos a hacerlo de manera local para nuestro proyecto. Quieres saber mas sobre como efectuar una instalación global, aqui.
Instalando las dependencias:
El Scrapping se va a ejecutar a este mismo Blog con la URL http://angelitodiaz.blogspot.com/ y el resultado de la inspeccion se grabara en un archivo TXT.
Como este es un trabajo autodidacta, de investigación y colaborativo, espero su ayuda ya que la salida la llevó al mismo directorio donde se aloja la aplicación, a un archivo de extensión TXT haciendo uso del File System (FS) que permite NODEJS. En este punto logré sacarlo, pero la salida no he podido formatearla como deseo:
Inspeccionamos la estructura que me brinda Blogger haciendo uso en Chrome del inspector para desarrolladores para la fecha de este post:

Observamos las etiquetas que nos interesan, article con la clase post, div con la clase post-header, span con la clase tag y span con la clase date.
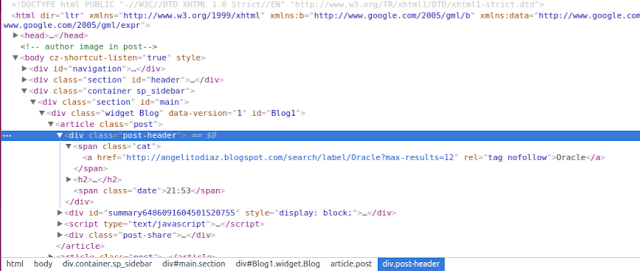
Allí la información que necesitamos.
El código del archivo Web-Scrapping.js:
La primeras 02 líneas hacen el llamado a las librerías Cheerio y Request. Cheerio hace la magia para atravesar fácilmente el DOM. y Request trabaja las llamadas HTTP. Quieres saber mas, ahi te deje los enlaces a la documentación.
La estructura principal básica de Request recibe la URL a tratar y una función de Callback con 3 parámetros. El error refiere a algún problema ocurrido, response un objeto con una variedad de datos resultado de la llamada y body el cuerpo del response.
Seguidamente verificamos que si no hay error y el servidor responde positivamente, vamos a hacer el Scrapping.
Lo primero llamar al método load de Cheerio para cargar la pagina y poder atravesar, luego almacenamos en una variable el contenido haciendo uso de la función trim para eliminar espacios en blanco al inicio y final de la cadena:
Mandamos el log a la consola para por costumbre ver una respuesta alli que es muy util cuando estamos desarrollando.
Con esto ya hemos atravesado el DOM y sacado la data que nos interesa.
El punto que no he podido perfeccionar a mi antojo es la salida de la consulta al archivo externo ya que no he podido formatearlo. Aqui pido tu ayuda y sugerencia. Node permite acceder a File System que pertenece al I/O Posix del sistema importando con el require('fs').
El resultado es el siguiente:

Yo deseo obtener un resultado que linea a linea haga lo mostrado.
Hasta aqui por el dia de hoy.
Exitos y recuerda, no dejes de compartir conocimiento.
Veamos apenas un poco de su magia. Vamos a atravesar el DOM para sacar algunos datos de la página cargada. Solo voy a mostrar lo sencillo que hice. Queda de tu parte extraer mayor data y experimentar a ver que tanto se puede hacer.
Lo primero es tener todo el entorno listo para desarrollar.
Voy a mostrar todo el trabajo corriendo en mi Dell Inspiron 5720 con Ubuntu 16.10 como OS matriz. Tengo instalado NODEJS y mis dependencias básicas son CHEERIO.JS y REQUEST.JS.
Vamos a hacerlo de manera local para nuestro proyecto. Quieres saber mas sobre como efectuar una instalación global, aqui.
Instalando las dependencias:
npm i -save cheerio requestEl Scrapping se va a ejecutar a este mismo Blog con la URL http://angelitodiaz.blogspot.com/ y el resultado de la inspeccion se grabara en un archivo TXT.
Como este es un trabajo autodidacta, de investigación y colaborativo, espero su ayuda ya que la salida la llevó al mismo directorio donde se aloja la aplicación, a un archivo de extensión TXT haciendo uso del File System (FS) que permite NODEJS. En este punto logré sacarlo, pero la salida no he podido formatearla como deseo:
ETIQUETA - HORA DE PUBLICACIÓN - TÍTULO DEL POSTInspeccionamos la estructura que me brinda Blogger haciendo uso en Chrome del inspector para desarrolladores para la fecha de este post:

Observamos las etiquetas que nos interesan, article con la clase post, div con la clase post-header, span con la clase tag y span con la clase date.

Allí la información que necesitamos.
El código del archivo Web-Scrapping.js:
La primeras 02 líneas hacen el llamado a las librerías Cheerio y Request. Cheerio hace la magia para atravesar fácilmente el DOM. y Request trabaja las llamadas HTTP. Quieres saber mas, ahi te deje los enlaces a la documentación.
La estructura principal básica de Request recibe la URL a tratar y una función de Callback con 3 parámetros. El error refiere a algún problema ocurrido, response un objeto con una variedad de datos resultado de la llamada y body el cuerpo del response.
request(url, function (error, response, body)Seguidamente verificamos que si no hay error y el servidor responde positivamente, vamos a hacer el Scrapping.
if (!error && response.statusCode==200)Lo primero llamar al método load de Cheerio para cargar la pagina y poder atravesar, luego almacenamos en una variable el contenido haciendo uso de la función trim para eliminar espacios en blanco al inicio y final de la cadena:
var $ = cheerio.load(html);var tag = $('article[class=post]>div[class=post-header]>span[class=cat]').text().trim();var titulo = $('article[class=post]>div[class=post-header]>h2').text().trim();var hora = $('article[class=post]>div[class=post-header]>span[class=date]').text().trim();Mandamos el log a la consola para por costumbre ver una respuesta alli que es muy util cuando estamos desarrollando.
console.log('Etiqueta: '+ tag);console.log('Titulo : '+ titulo);console.log('Fecha : '+ hora);console.log('-------------------------------------------------')Con esto ya hemos atravesado el DOM y sacado la data que nos interesa.
El punto que no he podido perfeccionar a mi antojo es la salida de la consulta al archivo externo ya que no he podido formatearlo. Aqui pido tu ayuda y sugerencia. Node permite acceder a File System que pertenece al I/O Posix del sistema importando con el require('fs').
fs.appendFile('mi_ingenieria_de_sistemas.txt', tag + '--' + hora + '--' + titulo );El resultado es el siguiente:

Yo deseo obtener un resultado que linea a linea haga lo mostrado.
ETIQUETA - HORA DE PUBLICACIÓN - TÍTULO DEL POSTHasta aqui por el dia de hoy.
Exitos y recuerda, no dejes de compartir conocimiento.
Comentarios
Publicar un comentario